通过使用presto结合Redis实现RocksDB数据SQL结构化
为什么使用presto结合redis的方式实现?
- 一开始我的目标是:因为presto支持自定义数据源插件开发,所以自己实现以RocksDB 作为数据源的插件,但是在开发过程中发现,因为RocksDB 数据源与业务耦合太紧,许多操作需要定制化开发,例如数据解密、数据反序列化、metadata映射等问题,这一步很难通过读取外部的配置文件或者通过presto客户端传递参数实现。所以我想借助第三方数据中间件进行业务与功能的去耦合。
实现以redis作为数据源,presto作为即席查询分析
什么是即席查询分析
- 即席查询分析(Ad Hoc):用户根据自身需求灵活选择查询条件,即席查询与普通应用查询最大的不同是普通的应用查询是定制开发的,而即席查询是由用户自定义查询条件的。
- 即席查询和分析的计算模式兼具了良好的时效性与灵活性,是对批处理,流计算两大计算模式有力补充。
开发步骤
- 在presto中配置redis有关参数,在etc/catalog/目录下新建redis.properties 配置如下:
1 | # 连接名称 |
注意点:因为在redis中存储数据结构为 hash,所以presto通过解析 key值生成结构化数据中的表名称和库名称,解析的分隔符默认为:
- 创建redis metadata文件,在redis.properties 中写定的metadata配置路径下新建redis.json文件,文件如下:
1 | { |
- 在redis客户端中写入数据,数据格式为HASH,进行测试:
1 |
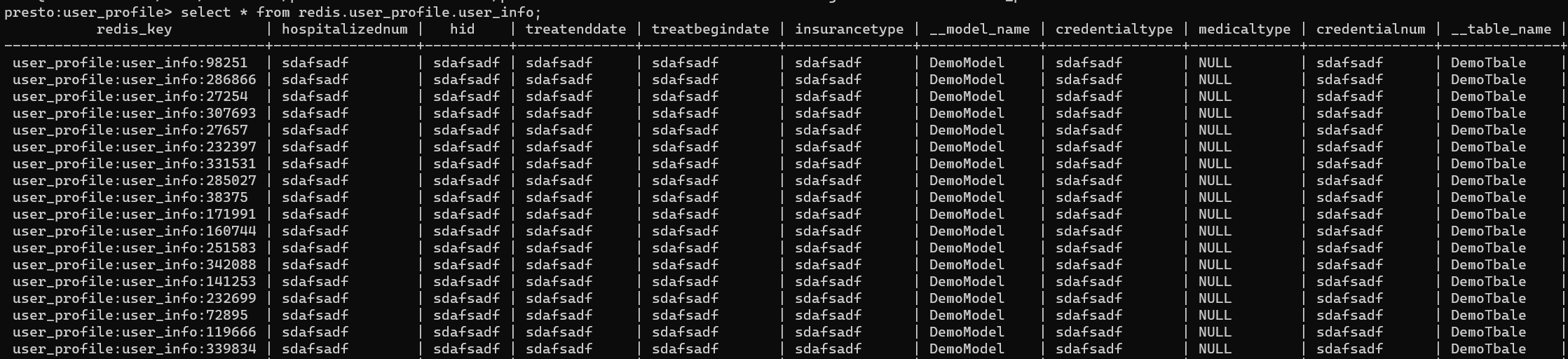
- 在presto客户端进行查询:
1 | ./presto --server localhost:8080 --catalog redis --schema user_profile(user_profile即为redis key:分隔符第一位) |
- 结果展示:
RocksDB中大批次数据写入Redis中
使用redis pipeline提高写入速度
Redis是使用客户端-服务端模型和请求/响应协议的TCP服务器,通常情况下一次请求需要以下步骤
1、客户端向服务端发送查询,以阻塞的方式从套接字中读取服务器响应
2、服务器处理命令并将响应发送给客户端
这种模式依赖于RTT(往返时间),如果有1000条数据插入,则会耗时1000*RTT
pipeline是将所有命令打包,通过一次网络参数发送至服务端,所以可以大大减少网络通信时间。
使用多线程处理模式提高写入速度
将对数据集进行拆分,规定每一个线程处理N条数据,并行写入Redis提高速度。
执行时间表
| 数据量 | 方案说明 | 耗时(MS) |
|---|---|---|
| 320000 | 不使用redis pipeline模式 | 291070 |
| 320000 | 使用redis pipeline | 25337 |
| 320000 | 使用 pipeline+多线程 | 9780 |