Sedona是一个基于spark的集群计算框架,可以大规模处理地理空间数据。Sedona扩展了Spark中数据结构RDD,使之可以兼容集群中地理空间数据,Sedona的SpatialRDD可以由普通RDD转换而来或者通过读取数据源而生成。
Sedona提供了开箱即用的空间SQL API和RDD API,SQL API 标准与PostgreSQL一致,RDD API支持Scala,Java,Python,R语言开发。
Sedona 支持读取的数据源
”spark 支持读取的数据源,Sedona都支持“
1、
CSV
2、HDFS
3、Amazon S3
4、ODPS
Sedona 支持解析的地理数据格式
1、WKT
2、WKB
3、GeoJSON
4、Shapefile
Sedona 内部的 Spatial RDD兼容7种空间类型:
- 点
- 多点
- 多边形
- 多个多边形
- 线条
- 多个线条
- 圆形
- Geometry集合
Sedona 处理大规模数据集的方式
空间数据分区
Sedona 中的Spatial RDD中的数据根据空间数据分布进行分区,附近的空间的对象会被放在同一分区内。空间分区具有两种效果:
(1)当执行针对特定空间区域的空间查询时,可以避免对空间不接近的分区进行不必要的计算,从而加快查询速度。
(2)将Spatial RDD切分为多个数据分区,每个分区的数据量接近,这样在集群计算时可以避免出现数据倾斜。
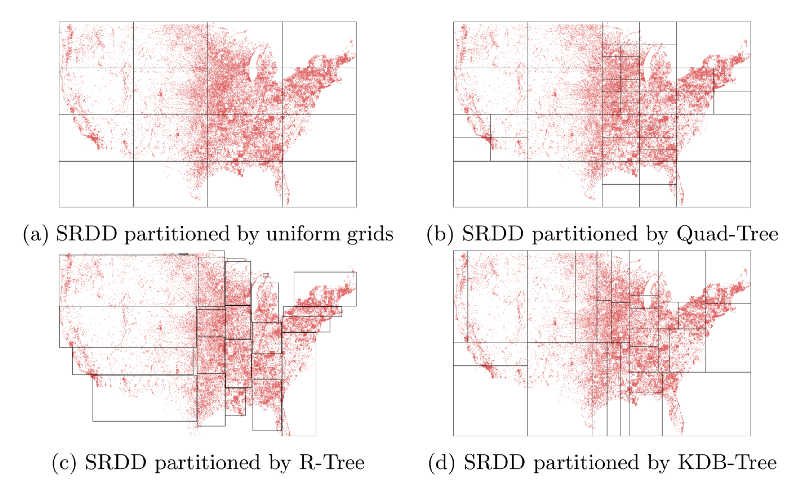
Sedona目前支持的空间分区模式有三种:
- KDB-Tree,
- Quad-Tree
- R-Tree
空间数据索引
Sedona 使用分布式空间索引对集群中的Spatial RDD进行索引,Sedona的分布式索引由两部分组成
(1)global index 全局索引,存储在master机器上,在spatial rdd 进行空间分区阶段生成,global index定位Spatial RDD中的空间分区边界框,global index 的目的是在空间查询时快速去除确定没有有效空间对象的空间分区。
(2)local index 本地索引,建立在Spatial RDD 的每一个空间分区里面,每一个local index只对自己空间分区的数据有作用,在空间查询中local index可以并行计算用于加速空间查询。
Spatial RDD定制化的序列化方式
Sedona针对空间对象和空间索引提供了定制化的序列化方式,Sedona序列化器可以将空间对象和空间索引序列化为压缩的字节数组,该序列化器比spark中常用的kyro序列化更快,在进行复杂空间操作(例如空间连接查询)时,占用内存较小。
序列化器还可以序列化和反序列化local index ,使用DFS(深度优先遍历)先父节点再写对应的子节点。
Sedona地理空间计算和JDBC连接PostgresSQL对比
计算效率对比
- 两种方案统一的Spark 集群配置都是60 instance , 2g instance memory, 2 instance core
- Sedona使用KDB-Tree作为空间分区算法,使用Quad-Tree作为空间索引算法
- PostgresSQL基于一台120核机器计算
| 方案名称 | 计算数据量 | 计算内容 | 耗时 | TPS |
|---|---|---|---|---|
| 分布式JDBC连接PostgresSQL地理计算 | 449655129条数据 | 计算5月份全量数据经纬度对应的路况 | 20h40m | 6044 |
| Spark+Sedona地理计算 | 449655129条数据 | 计算5月份全量数据经纬度对应的路况 | 2h20m2s | 53518 |
计算精准度对比
Spark+Sedona地理计算方案的计算结果有87%的结果数据可以和PostgresSQL计算结果匹配上
使用Sedona RDD API进行查询
配置依赖
Sedona版本和spark版本保持一致
初始化spark上下文
1 | val conf = new SparkConf() |
创建SpatialRdd
将spark dataframe转为SpatialRdd,并指定Geometry类型字段
1 | val roadRDD = Adapter.toSpatialRdd(roadWktDF, "geom_wkt", Seq("ref", "fclass")) |
构建空间索引
可以在SpatialRDD上构建分布式空间索引。目前,该系统提供两种类型的空间索引,QUADTREE和RTREE,作为每个分区的本地索引
1 | spatialRDD.buildIndex(IndexType.QUADTREE, false) // 在进行空间join查询时设置为true |
编写空间范围查询
空间范围查询返回位于地理区域内的所有空间对象。
例如,范围查询可能会在余杭找到所有公园,或在用户当前位置的一英里范围内返回所有公园。在入参方面,空间范围查询以一组空间对象和一个多边形查询窗口作为输入,并返回位于查询区域的所有空间对象。
1 | val rangeQueryWindow = new Envelope(-90.01, -80.01, 30.01, 40.01) //定义矩形空间窗口 |
编写K近邻查询
输入 K、查询点和空间RDD集合,查询距离查询点最近的K个空间RDD
编写空间连接查询
空间连接查询是将两个或多个数据集与空间距离相结合的查询,例如查询在500KM范围内有杂货店的加油站。
1 | val considerBoundaryIntersection = true |